November 21st 2017 - John Guibas & Tejpal Virdi
Introduction
The use of Deep Learning in autonomous cars has made profound improvements in the last few years. Computer Vision techniques have allowed us to pull down the hefty price of autonomous cars by using 2d cameras, rather than lidars or other complex sensors. In this blog post, we will look into two of the most important tasks in this domain: vehicle detection and depth estimation.
Semantic segmentation or detection involves partitioning an image into objects that are significant. This task has been heavily explored in Deep Learning with various architectures and datasets. Convolutional Neural Networks are unable to do this due to their pooling layers. Pooling compromises spatial representation, a necessary feature for segmentation since the location of the object in the image is important. On the contrary, Fully Convolutional Networks (FCNs) are extremely inefficient since the dimensionality of the input is never reduced, and thus passing a large number of parameters through the network. Researchers ended up finding a solution with the use of autoencoders. Autoencoders simplify the representation of the input with an encoder but then recover the details with a decoder. A popular autoencoder network used for segmentation is the U-Net.
The current popular approach for depth estimation while driving is through a 3d camera, such as a LiDAR. This sensor projects a laser onto objects in its view and measures the time it takes for the laser to come back to the sensor. This method is extremely accurate but the problem is that they are very expensive, with an average cost of $8,000 (previously $75,000 but Waymo changed this earlier this year). This price is not low enough for large-scale manufacturing and common use of driverless cars. However, recent developments in Computer Vision for depth estimation have allowed us to perform these tasks using a 2D camera (<$100).

In this post, we’ll use the classic Convolutional Neural Network to estimate depth given a road image. To do this, we must feed in road images with corresponding depth maps. We automate this process further by using stereoscopic images to create the depth maps algorithmically.
Segmentation
The encoder part of the U-Net is a standard ConvNet, which consists of a series of convolutional layers along with ReLU nonlinearities and max pooling operations. The output is a feature map that contains all the important information of the input image. The upsampling path involves a series of up-convolutions concatenated with the obtained feature maps, normal convolutions, and ReLU nonlinearities. This may seem like a standard convolutional autoencoder but the one thing that distinguishes it are the skip connections between parallel layers, where feature maps from the down convolutional process are concatenated to the corresponding feature maps in the up-convolutional process. The purpose of this is to retain the original important features since some are still present in the segmentation. Here is the exact architecture:
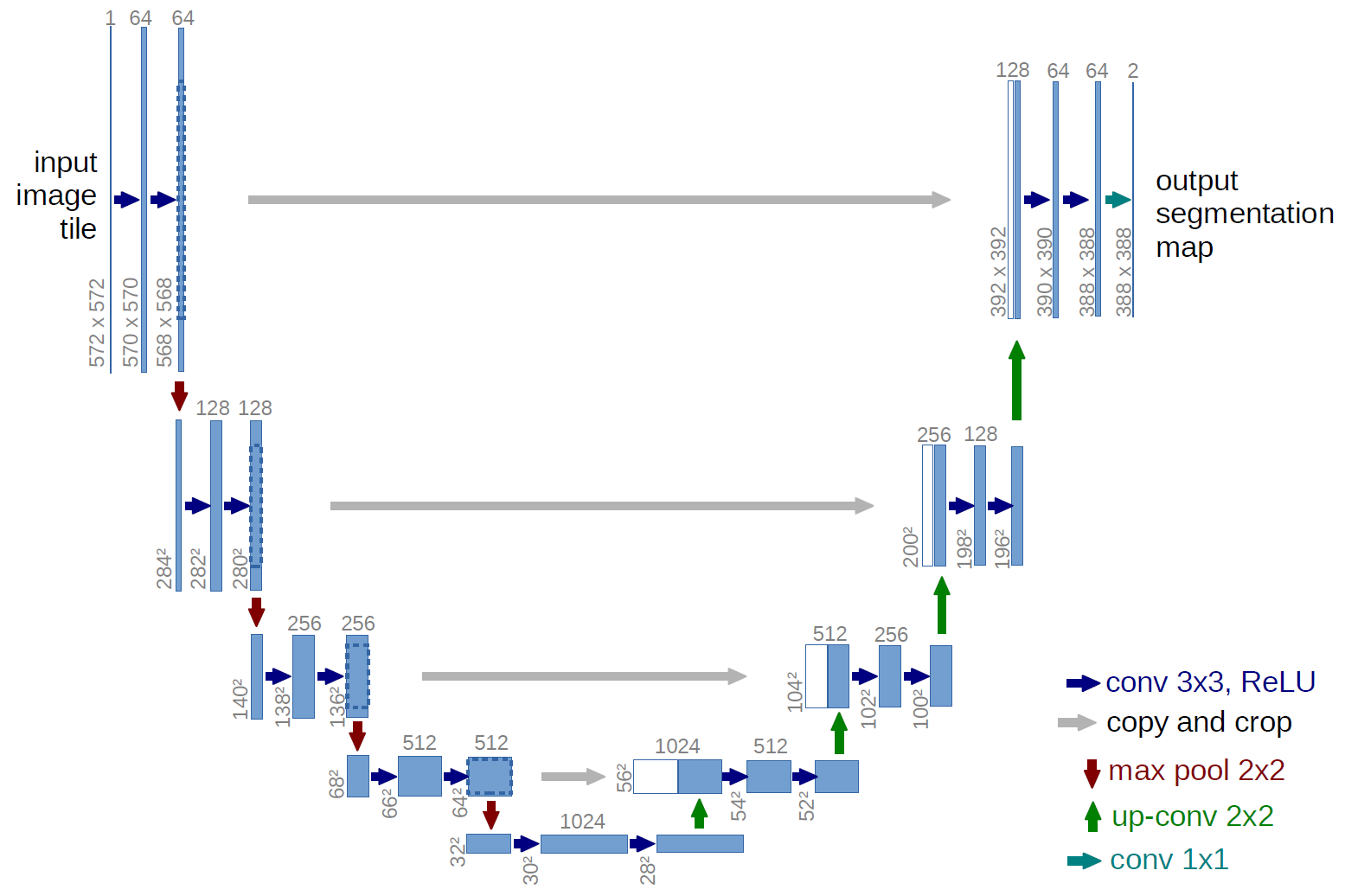
The original U-Net paper had the goal of segmenting biomedical images but this architecture has been seen to work for other segmentation tasks. We specifically utilize this segmentation network for detecting a car in a driving scene. We train the U-Net on 22,000 frames from a dashcam-video provided by Udacity. The many thousands of images show the network a large variance, meaning it does not look for the same exact car every time. Instead, it learns specific features found in every car, as low as certain edges and corners. This adaptation to new environments is crucial for a successful autonomous car.
Depth Estimation
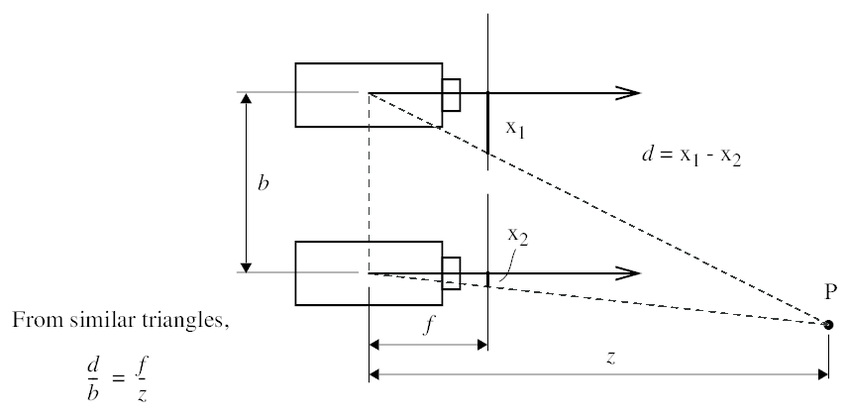
Humans are able to see depth due to their binocular vision. Each of our eyes inputs an image to our brain but these images are not exactly the same. Since our eyes are not located on the same point in space (parallax), there exists some offset between the images. In Computer Vision, these 2d images are known as stereo images.
Given two stereo images, one can calculate a disparity map, which is simply the difference between the two images. Using geometry, it is evident that the depth is inversely proportional to the depth.
In code:
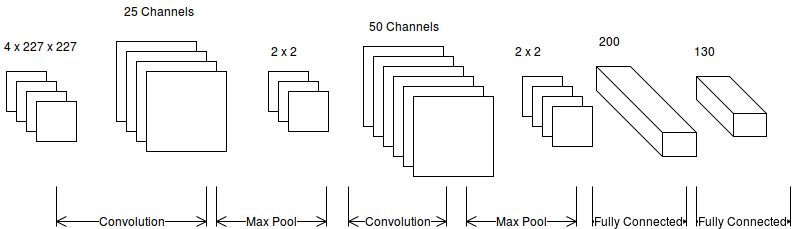
We then take one of the stereo images, along with its corresponding depth map, and feed it into a vanilla CNN. Once trained, we can do single-image depth estimation in real-time. Here is a review of the CNN architecture:
Results



Trained on implementation from here and here