November 22nd 2017 - John Guibas & Tejpal Virdi
An important imaging task is super-resolution: the process of enhancing the resolution of an image. Recently, researchers have gone at this problem using Deep Learning, and the methods have been successful. In this post, we look at a common medical procedure and show how it can be drastically improved with the use of GANs.
Introduction
Capturing real-time images of the insides of a patient may be difficult due to the restricted space and intricacies of the human body. In particular, a colonoscopy requires a video camera on a tube to be placed through the gastrointestinal tract, which goes to almost twenty-three feet long. The procedure is often accompanied by major discomfort, including cramping pains and abdominal swelling due to the aggressiveness of the procedure. Luckily, new methods have been introduced that can reduce the complexity of the procedure. With the development of nanotechnology, this examination can be done with a small capsule [1]. Also, recent advancements in transient electronics, have allowed for safe and painless medical diagnosis. However, the size of the device often compromises the quality of the images. A Low-resolution (LR) image cannot be used to its full potential, giving low-accuracies in classification models as well as difficulty for doctors when examining the images by eye.
Recently, Generative Adversarial Networks have been used for super-resolution [2]. Given an LR image, there are multiple possibilities for a corresponding and accurate HR image and the generator is trained to learn one of these mappings. Super-resolution has been commonly used in various domains such as satellite imaging, security, face-recognition, as well as medicine. The important features in a HR medical image are crucial for an accurate interpretation of the data.
This post analyzes the benefits of applying a super-resolution procedure to medical data, in terms of classification accuracy and qualitative results. It also enables the development of cheaper and smaller cameras and although compromising on quality, with the use of super-resolution technology, the small cameras can be successfully implemented.
Medical images are produced in two main forms: scans and photographs. Scans include X-rays, MRIs, CTs, etc. while common medical photography includes fundus photography and photography of internal tracts. Scan super-resolution has been explored by mapping MRI to CT scans as well as enhancing the resolution of low-dose scans. This post looks specifically into photography from colonoscopy procedures.
Data
We train the super-resolution GAN (SRGAN) on 1200 32x32 images from CVC-ColonDB [3].
Methods
The SRGAN follows the typical GAN format but the architectures for the discriminator and generator are different:
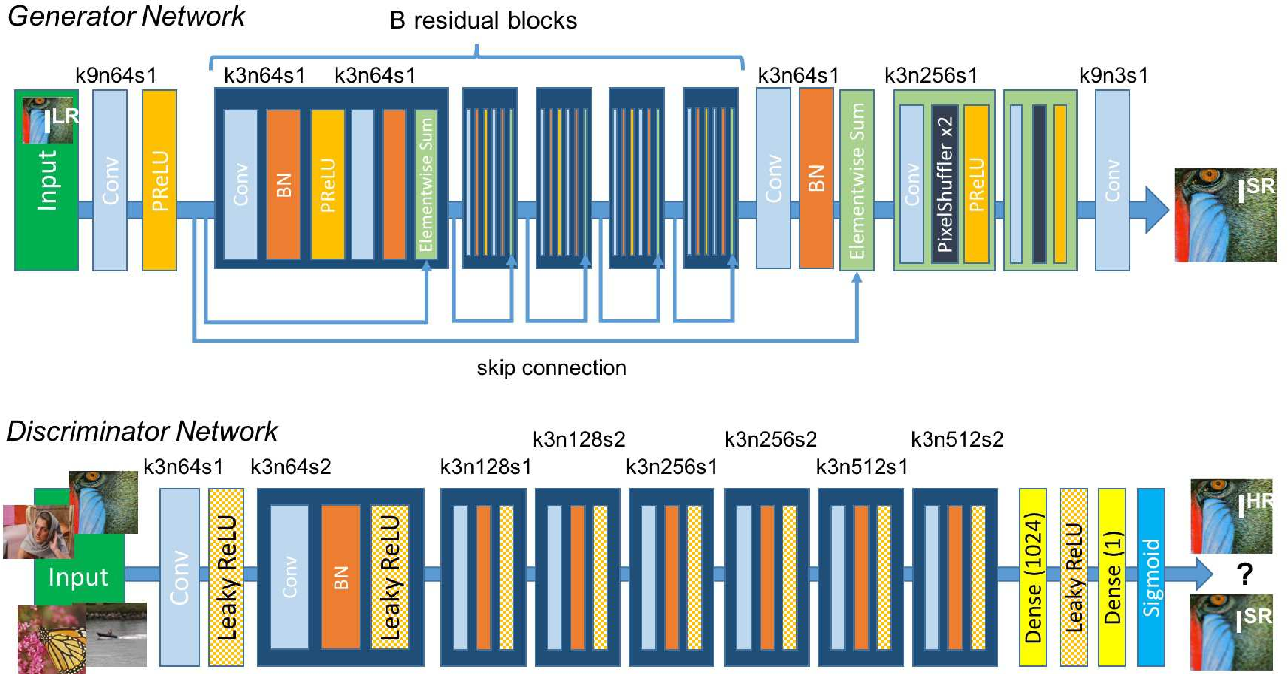
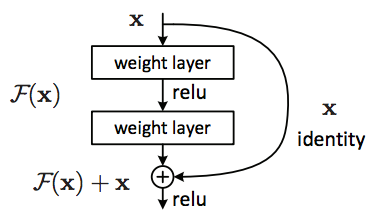
The most important feature of the Generator architecture is the B residual blocks. The residual block is the building block of the Residual Network (ResNet), which is one of the top architectures used for Image Recognition. The goal of any network is to find the mapping between an input and output. It does this by learning different functions along the way, one being the identity function. The identity function is very important since the output image is likely to have a similar structure to the input. A model without residual blocks never learns the exact identity function (input = output) but instead gets very close to it. The network would make tiny gradient changes to get closer to the function, resulting in the vanishing gradient problem. The ResNet fixes this by forcing the network to learn the identity mapping through an element-wise addition:
The discriminator is a pretty straightforward CNN. It uses a series of Convolution Layers, Leaky ReLUs, and Batch Normalization layers to learn the difference between high and super-resolution images. It takes in an input image and returns a scalar between 0 and 1, which is the certainty that the input is of super-resolution. A probability of 0.5 means that the discriminator cannot tell if the generated image is high-resolution or super-resolution.
SRGAN uses mean squared error (MSE) as the loss function, but the truth labels are a little different.
The minimization or solution space of a per-pixel loss function usually involves the generation of a smoother/more general image, which is counter-productive for super-resolution. Instead, SRGAN uses a perceptual loss, which has been proven effective and efficient for style transfer and super-resolution. Perceptual loss is based on comparing outputs to high-level features extracted from pretrained networks, specifically the VGG-19. This loss encourages the network to have similar features rather than exact pixel values to the original image. Although this may not perform well quantitatively, the sharper details from the use of a perceptual loss result in a qualitatively superior output.
Examples
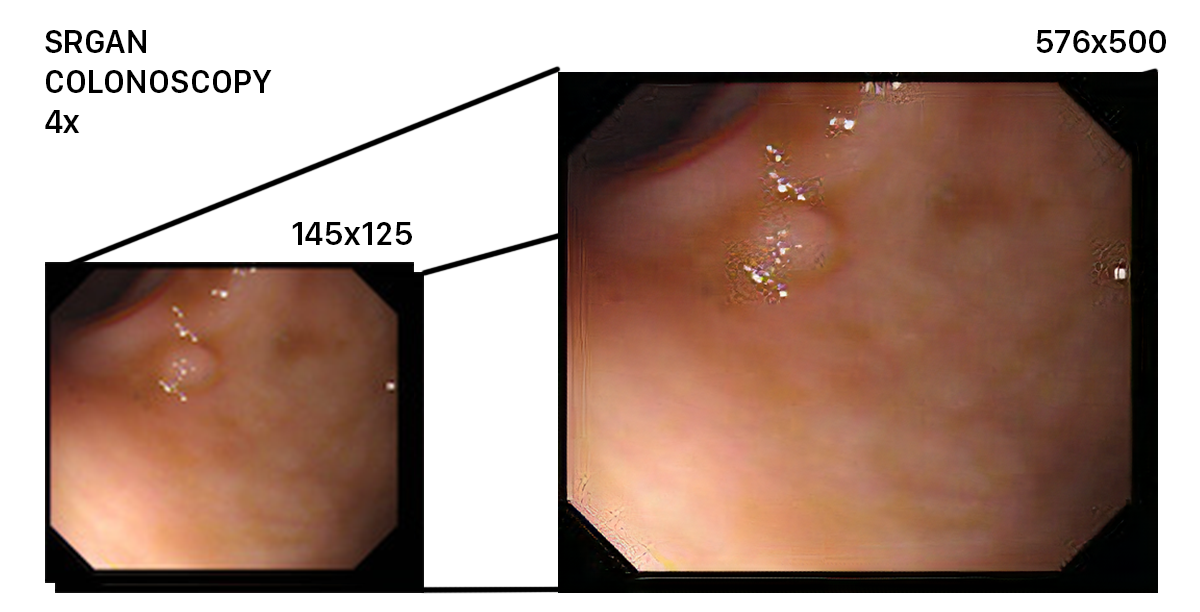
Here is an example image processed by SRGAN. As you can see, despite the low resolution of the initial image, the network was able to upscale it succesfully. However, it had a hard time dealing with spots of reflection.
References
- “PillCam Capsule Endoscopy.” PillCam Capsule Endoscopy - Given Imaging, www.givenimaging.com/en-int/Innovative-Solutions/Capsule-Endoscopy/Pages/default.aspx.
- Ledig, Christian, et al. “Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network.” [1609.04802] Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, 25 May 2017, arxiv.org/abs/1609.04802.
- “CVC Colon DB.” Machine Vision Group, mv.cvc.uab.es/projects/colon-qa/cvccolondb.